The REPRODUCE-ME Data Model and Ontology
The REPRODUCE-ME Data Model is a generic data model for the representation of scientific experiments with their provenance information. The aim of this model is to capture the general elements of scientific experiments for their understandability and reproducibility. An Experiment is considered as the central point of the REPRODUCE-ME data model. The model consists of eight components: Data, Agent, Activity, Plan, Step, Setting, Instrument, Material.
The following diagram shows an overview of the REPRODUCE-ME data model to represent a scientific experiment.
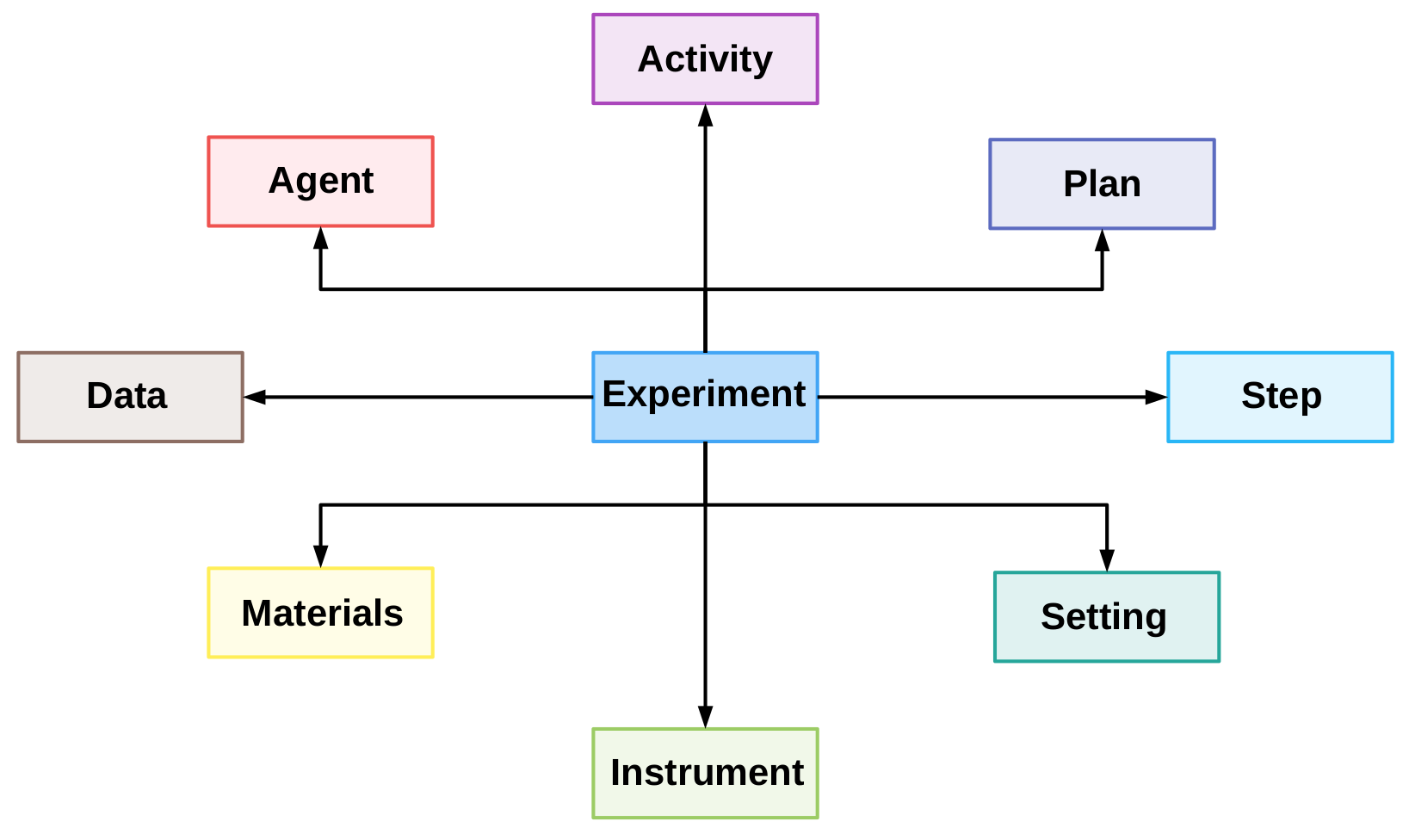
The REPRODUCE-ME Data Model forms a basis for the REPRODUCE-ME ontology. The REPRODUCE-ME ontology extended from PROV-O and P-Plan is used to represent the whole picture of an experiment describing the path it took from its design to result. It is extended from PROV-O to represent all agents, activities and entities involved in an experiment. It also extends from P-Plan to represent the steps, the input and output variables and the complete path taken from an input to an output of an experiment. We aim to enable end-to-end reproducibility of scientific experiments by capturing and representing the complete provenance of a scientific experiment using the REPRODUCE-ME ontology. Here we present a list of competency questions that are required to be answered for reproducing scientific experiments from the scientists from the Collaborative Research Centers (CRC ReceptorLight).
-
What are the input and output variables of an experiment?
-
Which are the methods and standard operating procedures used?
-
Which are the files and materials that were used in a particular step?
-
Which are the steps involved in an experiment which used a particular material?
-
What is the complete path taken by a scientist for an experiment?
-
Which are the instruments that are associated with an experiment and their settings when the output was generated?
-
Which are the agents directly or indirectly responsible for an experiment?
-
Who created this experiment and when? Who modified it and when?
-
Which are the publications or external resources that were referenced in each step of an experiment?
-
Scientific experiments
-
Input and output associated with an experiment
-
Execution Environmental attributes of an experiment
-
Experiment Materials and their preparation steps
-
Steps used in an experiment
-
Execution Order of steps and activities
-
The agents involved in an experiment and their role
-
Script/Jupyter Notebook execution in a multi-user environment provided by JupyterHub
-
The OME data model
-
Microscopic Image Acquisition properties
-
Bio-Formats
-
Instruments and their settings
Resources:
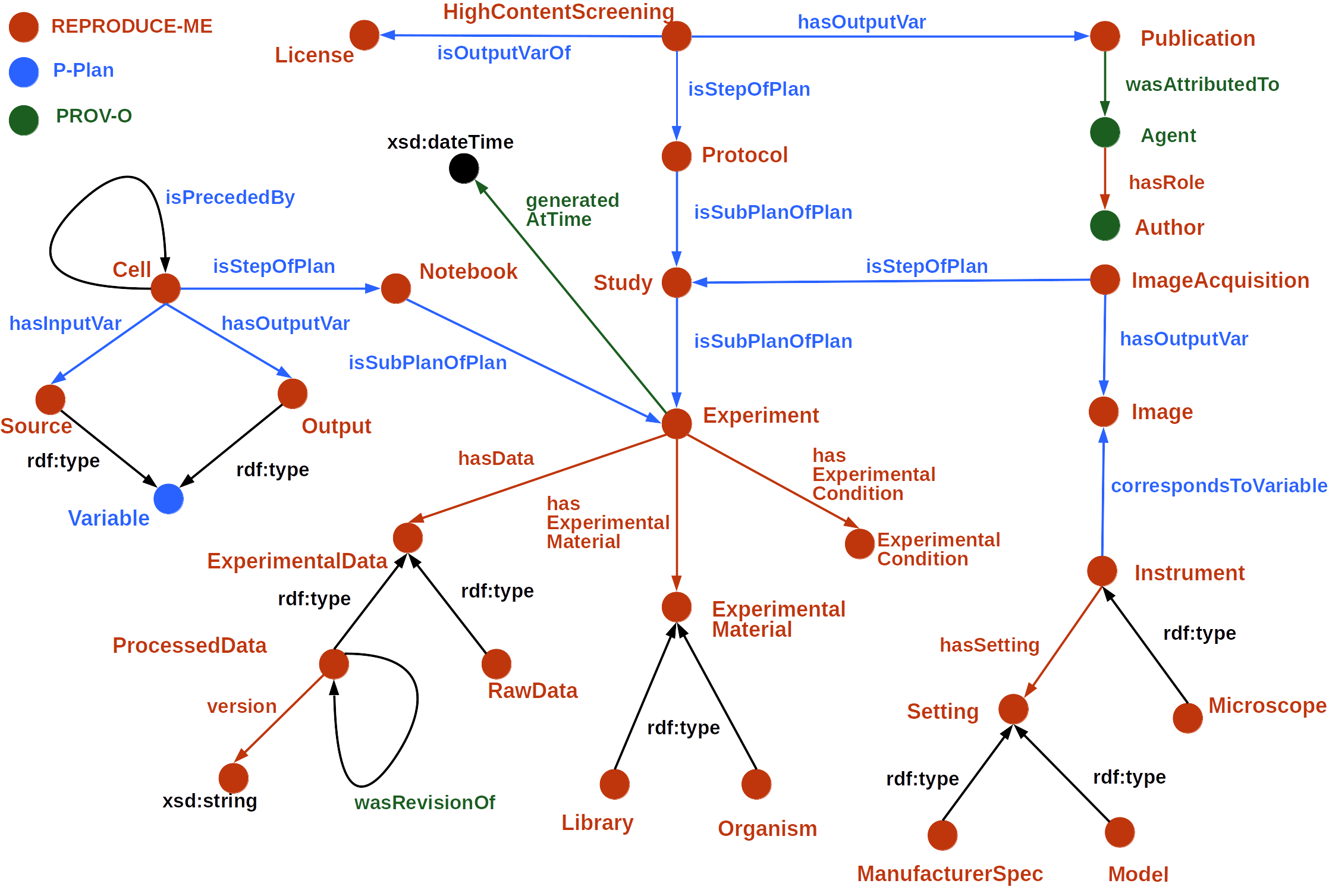
The following diagram shows how the REPRODUCE-ME ontology is used to describe the computational and non-computational parts of a scientific experiment taking into account the use case of life science experiments.
This work is licensed under Creative Commons Attribution-NonCommercial-ShareAlike 2.0 Generic License.